
A Practical Guide to Detecting Hallucinations in LLMs
A technical overview of various approaches in detecting model hallucinations along with sample Python implementations.

Overview

In recent months, Generative AI models have become incredibly popular. However, for wide enterprise adoption, inaccuracy of the generated output, a.k.a “hallucinations“, has emerged as one of the biggest roadblocks. In a previous article, we went over the basic concepts of Hallucinations, their causes and potential business impact on the enterprise. In this article, we will go over various techniques for mitigating Hallucinations in real-time, including some code examples (provided for free under an MIT license). Specifically, you will learn a) how to minimize the possibility of hallucinations before the model generates an output using the RAG architecture, b) how to further reduce the possibility of hallucinations using a post generation detector and c) the pros and cons of the various approaches. Note that some of the post output generation detectors that we describe here can also be used during offline evaluations which we will write about in a future article.
Using context for grounding and detection
Retrieval-Augmented Generation (RAG)
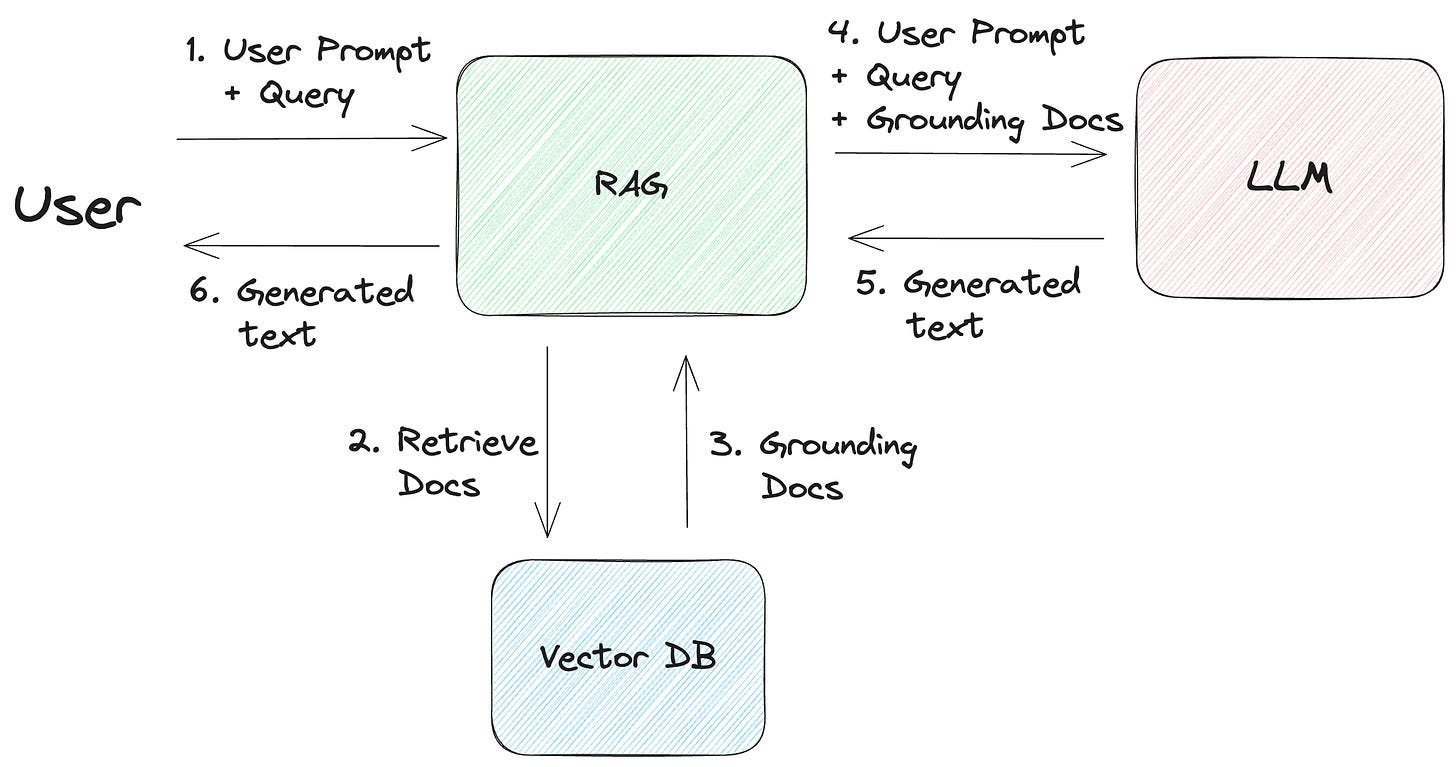
The RAG (Retrieval-Augmented Generation) architecture helps reduce hallucinations in Large Language Models (LLMs) by fetching relevant documents from a corpus to base model responses on. They divide the task into a retriever, which finds documents (typically via a Vector DB), and a generator, which creates text based on these documents, ensuring the response is grounded in factual information. This way, RAG based models counter hallucinations that often arise from unfounded inferences made by LLMs. They can be fine-tuned with human feedback to align better with factual accuracy and thus, minimize hallucinations, leading to more reliable text generation. Through this method, RAG based models contribute to a more reliable and accurate text generation, significantly minimizing hallucinations in LLMs. The code block below is an example RAG model taken from HuggingFace.
from transformers import AutoTokenizer, RagRetriever, RagModel
import torch
# Create the tokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/rag-token-base")
# Create the retriever
retriever = RagRetriever.from_pretrained(
"facebook/rag-token-base",
index_name="exact",
use_dummy_dataset=True
)
# Initialize with RagRetriever to do everything in one forward call
rag_model = RagModel.from_pretrained("facebook/rag-token-base", retriever=retriever)
# Inference example
inputs = tokenizer("How many people live in Paris?",return_tensors="pt")
outputs = rag_model(input_ids=inputs["input_ids"])Pros
Improves performance of models on data patterns that were not present in the training dataset.
Significantly reduces the possibility of hallucinations (specially extrinsic hallucinations).
Cons
Requires using appropriate infrastructure like a VectorDB to implement this.
Grounding limits model creativity. In certain applications, hallucination is a good thing; ex: when the model is used to create a story plot.
Great! Now that we have a mechanism to reduce hallucinations by a certain extent (~40% to 60%) before the model generates an output, how can we further reduce the risk of hallucination? A post generation detector can help further reduce risk by continuously monitoring your LLM for hallucinations. In the sections below, we describe approaches to implement such detectors.
Context based Hallucination Detection
These methods work when access to source data is available. This source data is typically a superset of what the model was trained on. The training data is a subset of the source dataset. The context data (that is retrieved by the RAG) is typically a subset of the training data. However, the context data can also be a completely separate out-of-domain set that is very different from the training dataset. This is typically passed to an LLM to improve its performance on out of domain data patterns.
Rogue-N Based Detection
ROUGE-N (Recall-Oriented Understudy for Gisting Evaluation) is a metric used to evaluate the quality of text generated by an LLM, especially in tasks like summarization and translation (that account for the majority of LLM use cases). The “N” represents the length of n-gram considered. Essentially, it compares the n-grams in the generated text to those in a reference text to compute the overlap, which helps in understanding the quality and relevance of the generated text. The metric provides values for recall, precision, and F1-score, offering a well-rounded view of how well the generated text aligns with the reference text. This code snippet is an implementation of a Rogue-N based hallucination detector given a reference text and a generated text. Here is how this utility can be used:
generated_summary = "The cat sat on the big rug."
reference_summary = "The cat sat on the mat."
rn_detector = RogueNHallucinationDetector(
metric_to_compare="f1_score",
threshold=0.8
)
res = rn_detector.detect(generated_summary, reference_summary)
print(res)
# Output: detector returns True since the f1_score of 0.727 is less than threshold of 0.8
# ({'precision': 0.6666666666666666, 'recall': 0.8, 'f1_score': 0.7272727272727272}, False)The model output contained the words ”Big rug” when it should have actually been the word “mat”. This is clearly an intrinsic hallucination. All good so far!
But, here is an example where this method fails:
generated_summary = "The cat sat down on the mat."
reference_summary = "The cat sat on the mat."
rn_detector = RogueNHallucinationDetector(
metric_to_compare="f1_score",
threshold=0.8
)
res = rn_detector.detect(generated_summary, reference_summary)
print(res)
# Output: detector returns True since the f1_score of 0.727 is less than threshold of 0.8
# ({'precision': 0.6666666666666666, 'recall': 0.8, 'f1_score': 0.7272727272727272}, True)This is not a hallucination since there is no difference in “sat” v/s “sat down”. Yet, this detector returns the same metrics as the previous case and based on our chosen threshold of the f1_score, it is classified as a hallucination. With this approach, choosing thresholds is extremely challenging with paraphrased outputs.
This approach is sometimes used to compare the generated output with the context retrieved from a RAG. The idea is to choose a threshold on the f1_score that best identifies the ideal proportion of the output that was part of the context. However, as shown above, it is already challenging to do this even with a reference summary. With a context, it becomes exponentially challenging (almost impractical) to choose thresholds.
Pros
Simple approach that may work well for certain summarization and translation tasks.
Small compute footprint and runs on commodity hardware.
Cons
Works best when there is a reference summary/translation available which is impractical in a real-world scenario. Comparing against a retrieved context is very challenging.
Does not consider semantic similarity between the reference and generated text.
Does not work well with other use cases like Code Generation and Q&A.
Picking a threshold for the f1_score, precision or recall requires an understanding of domain specific data patterns. Also, there is a need to tune this threshold periodically.
Provenance checks
This approach involves querying a corpus of source data to check if the LLM output is present in the source corpus. This can be implemented by leveraging the same Vector Database (Vector DB) that is used for the RAG process. The output is chunked, the embeddings of the resulting chunks are computed and the resulting embeddings are used to query the Vector DB to retrieve matching documents. The relevance score or a simple heuristic that leverages this score can be used to measure how close the generated output is to the retrieved documents. A more efficient alternative is to use the same context retrieved during the RAG process v/s querying the Vector DB again. Unlike the ROGUE-N, this approach does not require a reference summary.
Pros
Simple and easy to understand the intuition behind this approach: checking if the output is present in the source corpus is a reasonable way to check for deviations from the input.
Paraphrased output is handled reasonably well due to the semantic matching available via the Vector DB.
Cons
Hard to tune thresholds on the retrieved documents. May require training and maintaining an additional classifier that uses the relevance as an input.
Additional latency overhead due to the extra set of queries to the VectorDB makes this impractical in high scale, latency sensitive use cases.
Intensive in network IO when a large number of candidate documents are retrieved.
Does not work when source data is unavailable.
Aimon “Rely” Detector
We, at Aimon Labs, have developed a detector that is more intuitive than the simple ROGUE-N like approaches and far less resource intensive than provenance checks. This detector is available as part of the Aimon “Rely” product (see the “Recommended architecture to reduce hallucinations“ section below for a brief overview of the architecture). The deep learning model that powers this detector builds detailed representations of the source context and the target text (ex: LLM generated summary) and then compares the two to make a prediction about hallucinations at multiple levels of granularity (words, sentences, complete target text). The detector also provides attribution to the spans of text that are hallucinated. On a manually tagged internal dataset (corresponding to an enterprise use case), this first version of our detector is able to achieve 70% precision, 65% recall and has an accuracy of 72%. In comparison, a Rogue-N based approach comparing generated text to a context had 40% accuracy. We plan to run more comprehensive quantitative analyses comparing different approaches, the results of which we will publish in a later post. The code below shows a quick demo of the API that returns sentence level scores that help attribute hallucinations at the sentence level.
# Task: Summarize a ticket
# Aimon Rely detects hallucinations in the generated summary.
# Shortened context for illustration
context = "... TICKET: Trouble with API connectivity. We are experiencing trouble with the API connectivity for our User service on the production server. We are currently on v2.0.0 and would like to upgrade to v3.0.1 to resolve the connectivity issues. Case status changed to WIP by foocustomersupport.com Creation date 06/10/2022 11:55AM comments by agent.Hello bazcustomer.com. My name is Foo. ..."
# Shortened summary for illustration
summary = "... The service was upgraded successfully to v3.0.1 and the API connectivity issues were resolved post the upgrade. The agent had to take additional measures to resolve the database configuration issues. Resolution: The API connectivity issue of the customers User service was resolved successfully by upgrading the service to v3.0.1."
am_detector = AimonRelyDetector()
res = am_detector.detect(context, summary)
print(res.json())
# Output: is_hallucinated is true because one of the sentences of the
# summary contains hallucinated text: "defective battery
# causing overheating".
"""
[
{
"is_hallucinated": "True",
"sentences": [
...
{
"score": 0.0,
"text": "The service was upgraded successfully to v3.0.1 and the API connectivity issues were resolved post the upgrade."
},
{
"score": 0.99869,
"text": "The agent had to take additional measures to resolve the database configuration issues."
},
{
"score": 0.0,
"text": "Resolution The API connectivity issue of the customers User service was resolved successfully by upgrading the service to v3.0.1."
}
]
}
]
"""Pros
No need to pick thresholds. Interpretable sentence level probabilities.
Runs on commodity hardware.
Low latency and low resource overhead.
Easily customizable to a specific vertical.
Cons
To achieve the best performance, one-time fine tuning is needed.
Reach out to us at info@aimon.ai if you are interested in this approach.
Hallucination Detection Without Source Data
Reducing hallucinations without grounding via RAGs or when the source data is unavailable is very challenging. We do not recommend using a context-free post generation detector in practice. However, there is healthy academic research interest in this area. We describe a couple of methods that we found interesting.
Uncertainty-based assessment (UBA)
LLMs are trained on vast amounts of text which enables them to predict the next word in a sequence proficiently. Paraphrasing from the SelfCheckGPT paper: in the prompt "Lionel Messi is a _", the LLM, recognizing Messi's name from training, is likely to accurately fill in "footballer". Conversely, with lesser-known names like in "John Smith is a _", the model may falter, giving rise to a flat probability distribution, which could lead to an inaccurate word being generated. This behavior highlights how analyzing the probability distribution and associated uncertainty can help differentiate factual outputs from hallucinations—with confident predictions indicating factual information and flat or uncertain distributions signaling potential inaccuracies.This code snippet provides an implementation of computing the entropy and the uncertainty given token level probabilities. The max_neglog_p value measures the sentence’s likelihood by assessing the least likely token in the sentence.
# Assume a simplified scenario with 3 sentences and a vocabulary of 5 words
# Each row in prob_matrix represents a sentence, and each column represents the probability of a word in the vocabulary
prob_matrix = np.array([
[0.7, 0.1, 0.1, 0.05, 0.05], # Sentence 1
[0.2, 0.3, 0.1, 0.2, 0.2], # Sentence 2
[0.1, 0.1, 0.6, 0.1, 0.1] # Sentence 3
])
max_entropy_value = max_entropy(prob_matrix)
print(f'Maximum Entropy: {max_entropy_value}')
max_neglogp_value = max_neg_log_p(prob_matrix)
print(f'Maximum Neg Log P: {max_neglogp_value}')
# Output
# Maximum Entropy: 1.5571130980576458
# Max value for each sentence
# Maximum Neg Log P: [2.99573227 2.30258509 2.30258509]While experimenting with this approach, we found that making a generalizable hallucination decision based on the entropy or uncertainty scores is very hard to achieve.
Pros
Fairly simple to implement.
Does not need access to the internal state of the LLM other than the output probabilities.
Small compute footprint once the output probabilities have been obtained.
Cons
Output probabilities may not always be available from the LLM.
Hard to pick thresholds on the resulting entropy scores.
SelfCheckGPT
This is a prominent context-free method that utilizes a sampling-based approach to check the factual accuracy of LLM-generated responses by analyzing the consistency in multiple responses for the same prompt. Inconsistent responses hint at the possibility of hallucinations.
Pros
Works across multiple LLM use cases.
Does not need access to output probabilities or the inner state of the LLM.
Cons
Very expensive from both a cost and latency perspective since multiple samples need to be generated from the LLM for the same prompt.
A few other noteworthy approaches are blackbox methods using a Proxy LLM,SELF-FAMILIARITY and Self-Contradiction based detection.
Recommended architecture to reduce hallucinations
The figure below illustrates our recommended architecture to reduce hallucinations from LLMs. This architecture uses both a RAG to generate context and a hallucination detector to detect issues in the generated output. The user prompt, context documents and the generated text are sent to the hallucination detector that primarily detects if the output consists of factual inconsistencies using the context as a reference. The feedback from the detector can be used to restate prompts or fine tune the LLM models themselves. If you want a turnkey solution to implement this architecture, you can leverage Aimon Rely that provides a hallucination detector and a framework for a feedback loop for improving the models.

Comparison of various approaches
In the table below, we compare different approaches for detecting hallucinations after the LLM generates an output.
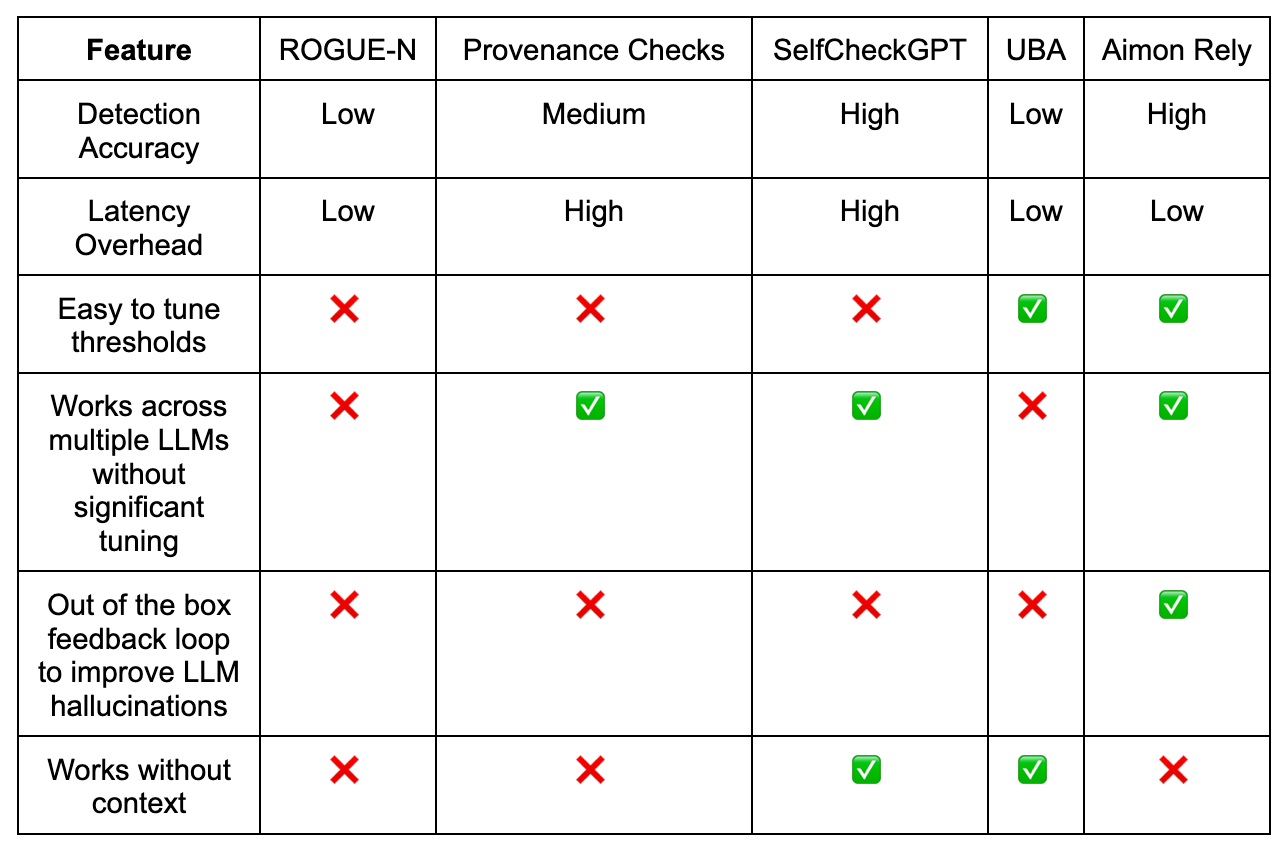
Conclusion
In this post, we talked about how the RAG architecture helps reduce hallucinations. We also went over popular post-generation detection methods that can help further minimize the possibility of hallucinations at runtime. To reduce hallucinations, we recommend using a RAG and a post generation hallucination detector as described above. As LLMs start powering more prime time applications, it becomes crucial to continuously detect and reduce hallucinations.
If you found this post useful, please follow us on LinkedIn. If you would like to learn more about our product and get access to our early version of the product, please send us a note on info@aimon.ai.
Acknowledgements
Special thanks to Ehtsham Elahi and Puneet Anand for contributing to this article.